현재 개발하고 있는 서비스에는 검색 기능이 존재한다.

콘텐츠 제목, 크리에이터의 이름, 콘텐츠에 나오는 장소들의 이름 중 하나에 걸리면 검색 결과로 나오는 구조이다.
현재는 데이터가 별로 없어서 검색이 느리다고 체감한 적이 없었다. 그런데 만약 많은 데이터가 쌓이면 검색 속도가 얼마나 느려질까? 많이 느리다면 속도를 어떻게 개선할 수 있을까?
이 글을 읽으면 좋은 대상은 아래와 같다.
- 검색 기능을 구현하려는 사람, MySQL의 fulltext index과 전문 검색 기능을 도입하려는 사람
- LIKE 쿼리를 통해 검색 기능을 구현한 사람
📍 쿼리 속도 테스트 환경
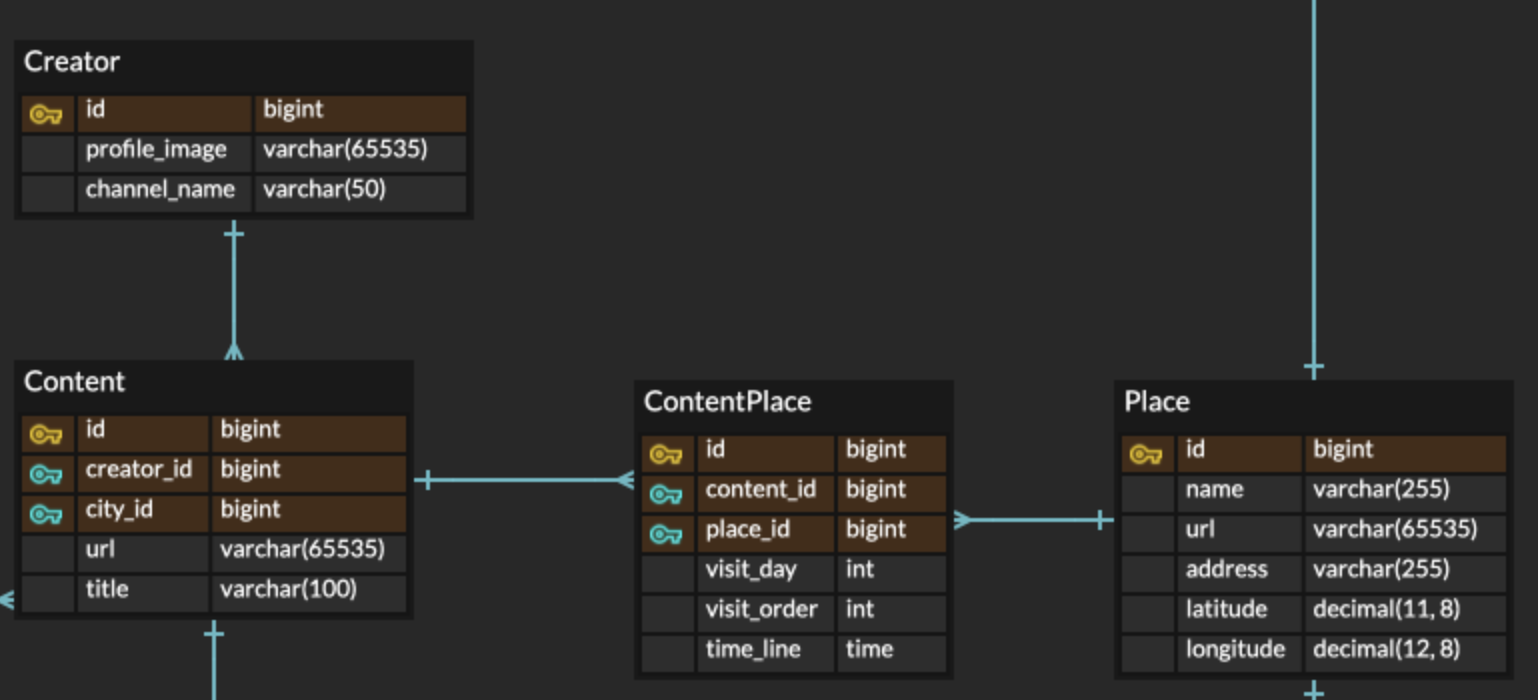
검색에 활용되는 테이블은 content, creator, place이고, 연관관계를 생각했을 때 총 4개의 테이블을 이용한다.
t4g.small 볼륨의 ec2에 MySQL을 띄우고, 테스트용 db를 만들어 더미 데이터를 주입했다.
검색의 대상이 되는 3개의 테이블에 더미데이터를 주입했다. 더미 데이터 생성에는 dataFaker라는 라이브러리를 사용했다.
핵심 테이블(콘텐츠) 10만개 기준
모든 데이터는 현재 수집된 데이터 (2025.09.26)의 비율을 기반으로 추정
콘텐츠 100,000개
크리에이터 7,500명 (10만개의 콘텐츠 기준으로 7,500명의 크리에이터가 필요할 것이라 가정)
콘텐츠 속 장소 2,000,000개 (콘텐츠 하나 당 20개의 장소가 있을 것이라 가정, 콘텐츠 * 20)
장소 1,700,000개 (콘텐츠 속 장소에서 중복되는 장소를 고려하여 콘텐츠 속 장소보다 낮은 값 설정, 콘텐츠 * 17)📍 현재 검색 쿼리, 성능
개선 전 쿼리는 이렇다.
SELECT DISTINCT c.*
FROM content c
JOIN creator cr ON c.creator_id = cr.id
LEFT JOIN content_place cp ON c.id = cp.content_id
LEFT JOIN place p ON cp.place_id = p.id
WHERE c.title LIKE '%느좋%'
OR cr.channel_name LIKE '%느좋%'
OR p.name LIKE '%느좋%'
ORDER BY c.id DESC;
4개의 테이블을 조인하고, 3개의 조건이 존재하며, LIKE 조건을 사용하고 있다.
그러면 이 쿼리가 문제가 있는지 알아보기 위해, 쿼리 실행 시간를 측정하고 explain 키워드를 이용해 실행 계획을 확인할 것이다.
(앞으로 이 글에서 언급하는 실행 시간은, 동일한 쿼리를 총 6회 수행한 뒤 첫 번째 실행을 제외한 나머지 5회의 평균값이다.)
✔️ 실행 시간
개선 전 쿼리는 평균적으로 2.311초 소요되는 것으로 측정할 수 있었다.
✔️ 실행 계획
+----+-------------+-------+------------+--------+----------------+----------------+---------+-------------------+------+----------+---------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+----------------+----------------+---------+-------------------+------+----------+---------------------------------+
| 1 | SIMPLE | cr | NULL | ALL | PRIMARY | NULL | NULL | NULL | 7504 | 100.00 | Using temporary; Using filesort |
| 1 | SIMPLE | c | NULL | ref | fk_creator_id | fk_creator_id | 9 | turip.cr.id | 13 | 100.00 | NULL |
| 1 | SIMPLE | cp | NULL | ref | fk_content_id | fk_content_id | 9 | turip.c.id | 1 | 100.00 | Distinct |
| 1 | SIMPLE | p | NULL | eq_ref | PRIMARY | PRIMARY | 8 | turip.cp.place_id | 1 | 100.00 | Using where; Distinct |
+----+-------------+-------+------------+--------+----------------+----------------+---------+-------------------+------+----------+---------------------------------+
실행 계획을 확인했을 때, creator 테이블에 대한 개선이 필요해 보인다. type이 ALL인데, 이는 풀 테이블 스캔이 일어난다는 의미이다.
join하는 부분에서는 creator의 pk만을 사용하고 있기에, 문제는 where의 channel_name 컬럼을 이용하는 부분이다.
WHERE cr.channel_name LIKE '%느좋%'
그럼 풀 스캔을 방지하기 위해 channel_name 컬럼에 인덱스를 추가한 뒤 다시 실행 계획을 확인해보자.
+----+-------------+-------+------------+--------+----------------+------------------+---------+-------------------+------+----------+----------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+----------------+------------------+---------+-------------------+------+----------+----------------------------------------------+
| 1 | SIMPLE | cr | NULL | index | PRIMARY | idx_channel_name | 203 | NULL | 7504 | 100.00 | Using index; Using temporary; Using filesort |
| 1 | SIMPLE | c | NULL | ref | fk_creator_id | fk_creator_id | 9 | turip.cr.id | 13 | 100.00 | NULL |
| 1 | SIMPLE | cp | NULL | ref | fk_content_id | fk_content_id | 9 | turip.c.id | 1 | 100.00 | Distinct |
| 1 | SIMPLE | p | NULL | eq_ref | PRIMARY | PRIMARY | 8 | turip.cp.place_id | 1 | 100.00 | Using where; Distinct |
+----+-------------+-------+------------+--------+----------------+------------------+---------+-------------------+------+----------+----------------------------------------------+
실행 계획의 type은 index로 바뀌었지만, rows 값을 보면 여전히 풀 스캔이 이뤄지고 있음을 확인할 수 있다. 즉, 인덱스를 생성했음에도 B+Tree 특성 중 하나인 효율적인 범위 탐색을 이용하지 못한 것이다.
이유를 간단히 설명하자면, B+Tree 인덱스가 앞 글자부터 순차적으로 비교하는 구조이기 때문이다. 하지만 %keyword% 형태의 검색은 문자열 앞부분에 어떤 글자가 올지 모르니 정렬된 구조를 활용할 수 없다. 즉, 인덱스를 추가했음에도 전혀 이용하지 못하는 것이다.
이러한 경우를 위해 MySQL에서 제공하는 것이 fulltext index이다.
📍 fulltext index
fulltext index는 어떤 방식으로 동작하길래, 앞뒤에 뭐가 올지 모르는 상황에서 효율적인 탐색이 가능해질까?
fulltext index는 B+Tree 구조가 아니라, 역색인(inverted index) 구조로 저장된다. B+Tree 구조의 일반 인덱스는 ‘이 행(row)에 어떤 값이 들어 있는지’를 알려주지만, 역색인 구조의 fulltext 인덱스는 ‘이 값(단어)이 들어 있는 행들이 어디 있는지’를 알려준다.
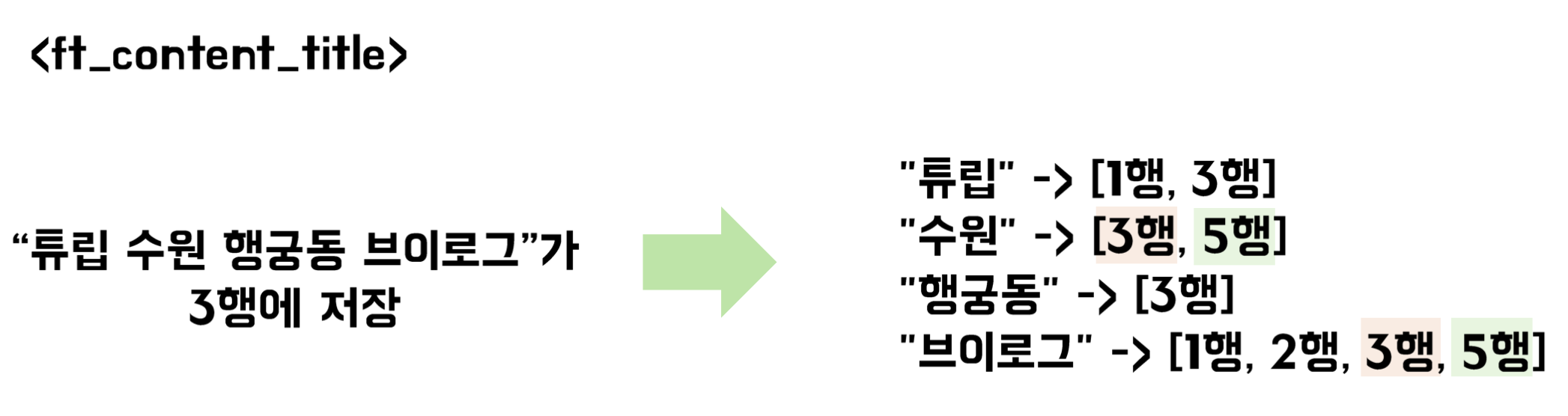
content 테이블에 title이 "튜립 수원 행궁동 브이로그"인 행이 id=3으로 저장되어 있다고 가정하자.
content.title에 fulltext index를 적용하면, 띄어쓰기를 기준으로 잘라서 토큰화(tokenize)한다. 그리고 이 "튜립", "수원", "행궁동", "브이로그"라는 토큰 모두 id=3에 대응한다고 저장해둔다.
이후 검색 쿼리에서 "수원" 키워드가 포함된 content를 알고 싶을 때(LIKE %수원%과 같은 의미), "수원"이라는 토큰에 대응하는 행들을 확인할 수 있다.
토큰화의 방법도 여러가지가 있다.
ALTER TABLE content ADD FULLTEXT INDEX idx_title (title);기본 파서는 위의 예시처럼 공백을 기준으로 토큰화한다. 하지만 이 방식에는 한계가 있는데, 예를 들어 "행궁"을 검색하면 "튜립 수원 행궁동 브이로그" 같은 문장은 결과에 포함되지 않는다. 또한 이 경우 기본 토큰 길이가 3으로 적용된다. 또한 기본 설정에서는 토큰 최소 길이가 3이라서, "행궁"처럼 두 글자로 된 단어는 토큰화조차 되지 않는다.
ALTER TABLE content ADD FULLTEXT INDEX idx_title (title) WITH PARSER ngram;ngram tokenizer를 사용하면, 공백 기준이 아니라 글자수를 기준으로 토큰화할 수 있다. "브이로그"를 size 2로 토큰화하면, "브이", "이로", "로그"가 될 것이다. ngram의 기본 size는 2인데 이 설정은 쿼리를 통해 변경할 수는 없고, 직접 설정 파일을 수정해야 한다.
📍 fulltext index 사용하는 쿼리, 성능
검색이 적용되는 컬럼들에 fulltext index를 추가해보자. 우리 서비스는 유연한 검색을 위해 ngram 파서를 사용하기로 했고, ngram 크기는 일단 기본값인 2로 설정했다.
ALTER TABLE content ADD FULLTEXT INDEX idx_title (title) WITH PARSER ngram;
ALTER TABLE creator ADD FULLTEXT INDEX idx_channel_name (channel_name) WITH PARSER ngram;
ALTER TABLE place ADD FULLTEXT INDEX idx_name (name) WITH PARSER ngram;
fulltext index를 활용하여 검색하려면, MATCH AGAINST 쿼리를 이용해야 한다. 따라서 쿼리 자체를 아래처럼 바꿔야 한다.
SELECT DISTINCT c.*
FROM content c
JOIN creator cr ON c.creator_id = cr.id
LEFT JOIN content_place cp ON c.id = cp.content_id
LEFT JOIN place p ON cp.place_id = p.id
WHERE MATCH(c.title) AGAINST('+느좋' IN BOOLEAN MODE)
OR MATCH(cr.channel_name) AGAINST('+느좋' IN BOOLEAN MODE)
OR MATCH(p.name) AGAINST('+느좋' IN BOOLEAN MODE)
ORDER BY c.id DESC;
✔️ 실행 시간
인덱스를 걸어주지 않았을 때와 비슷하게 2.212초가 나온다. 뭔가 이상하니 실행 계획을 확인해보자.
✔️ 실행 계획
+----+-------------+-------+------------+--------+----------------+----------------+---------+-------------------+------+----------+---------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+----------------+----------------+---------+-------------------+------+----------+---------------------------------+
| 1 | SIMPLE | cr | NULL | ALL | PRIMARY | NULL | NULL | NULL | 7504 | 100.00 | Using temporary; Using filesort |
| 1 | SIMPLE | c | NULL | ref | fk_creator_id | fk_creator_id | 9 | turip.cr.id | 13 | 100.00 | NULL |
| 1 | SIMPLE | cp | NULL | ref | fk_content_id | fk_content_id | 9 | turip.c.id | 1 | 100.00 | Distinct |
| 1 | SIMPLE | p | NULL | eq_ref | PRIMARY | PRIMARY | 8 | turip.cp.place_id | 1 | 100.00 | Using where; Distinct |
+----+-------------+-------+------------+--------+----------------+----------------+---------+-------------------+------+----------+---------------------------------+
fulltext index를 추가했으니 이제 풀 테이블 스캔이 일어나지 않을 것이라고 생각했는데, 여전히 type이 ALL로 나오는 것을 확인할 수 있다. 여러 테이블을 조인하고 복수의 WHERE 조건을 걸어주는 경우에는, 옵티마이저가 풀스캔이 더 효율적이라고 판단한다고 추론했다.
그래서 적용해본 방법은, UNION을 통해 WHERE 조건을 분리하는 것이다.
📍 UNION 활용하기
SELECT c.id, c.creator_id, c.title
FROM content c
WHERE MATCH(c.title) AGAINST('+느좋' IN BOOLEAN MODE)
UNION
SELECT c.id, c.creator_id, c.title
FROM content c
JOIN creator cr ON c.creator_id = cr.id
WHERE MATCH(cr.channel_name) AGAINST('+느좋' IN BOOLEAN MODE)
UNION
SELECT c.id, c.creator_id, c.title
FROM content c
JOIN content_place cp ON c.id = cp.content_id
JOIN place p ON cp.place_id = p.id
WHERE MATCH(p.name) AGAINST('+느좋' IN BOOLEAN MODE)
ORDER BY id DESC;
각 select 절에서 조건이 1개씩 걸려있기 때문에, fulltext index를 활용해 데이터를 선별한 다음에 join을 할 것이라고 기대했다.
✔️ 실행 시간
평균 0.308초 걸렸다. 기존에 비해 약 7.5배 빨라졌다.
✔️ 실행 계획
+----+--------------+--------------+------------+----------+--------------------------+------------------+---------+-------------+-------+----------+-----------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------+--------------+------------+----------+--------------------------+------------------+---------+-------------+-------+----------+-----------------------------------+
| 1 | PRIMARY | c | NULL | fulltext | idx_title | idx_title | 0 | const | 1 | 100.00 | Using where; Ft_hints: no_ranking |
| 2 | UNION | cr | NULL | fulltext | PRIMARY,idx_channel_name | idx_channel_name | 0 | const | 1 | 100.00 | Using where; Ft_hints: no_ranking |
| 2 | UNION | c | NULL | ref | fk_creator_id | fk_creator_id | 9 | turip.cr.id | 13 | 100.00 | NULL |
| 3 | UNION | p | NULL | fulltext | PRIMARY,idx_name | idx_name | 0 | const | 1 | 100.00 | Using where; Ft_hints: no_ranking |
| 3 | UNION | c | NULL | ALL | PRIMARY | NULL | NULL | NULL | 99101 | 100.00 | NULL |
| 3 | UNION | cp | NULL | ref | fk_content_id | fk_content_id | 9 | turip.c.id | 1 |10.00 | Using where |
| 4 | UNION RESULT | <union1,2,3> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary; Using filesort |
+----+--------------+--------------+------------+----------+--------------------------+------------------+---------+-------------+-------+----------+-----------------------------------+
fulltext index를 만들어준 3개의 테이블 모두 인덱스를 잘 타는 것을 확인할 수 있다.
📍 TestContainers 도입하기
전문 검색 쿼리는 MySQL 전용 쿼리인데, 테스트코드는 h2 환경에서 동작한다. 이 경우 검색 기능만 MySQL을 기반으로 동작하게 하기 위해 SpringBoot가 지원하는 TestContainers(https://docs.spring.io/spring-boot/reference/testing/testcontainers.html)를 사용했다.
TestContainers는 특정 테스트를 실행하기 전에 도커 컨테이너를 띄우고, 끝나면 컨테이너를 종료하는 기능을 지원한다. (로컬 실행 환경에 도커 컨테이너를 띄우는 것이기 때문에, 도커가 설치되어 있어야 한다.)
@TestConfiguration
public class TestContainerConfig {
@Bean
@ServiceConnection
public MySQLContainer<?> mySQLContainer() {
return new MySQLContainer<>("mysql:8.0.42")
.withUsername("root")
.withPassword("rootpwd")
.withDatabaseName("test_db");
}
}
각 테스트별로 컨테이너를 띄우고 종료하는 과정을 반복하면 테스트 실행 시간이 길어질 것이므로, MySQL이 띄워진 컨테이너를 빈으로 등록해두고 활용하자. 하나의 컨테이너를 공유하기 때문에, 사용하는 곳에서 beforeEach / afterEach로 데이터 지워줘야 한다.
@DataJpaTest
@Import(TestContainerConfig.class)
class ContentRepositoryTest {
...
}
테스트 클래스에서 MySQL 컨테이너 빈을 등록한 설정 파일을 적용하면, MySQL을 기반으로 테스트를 실행할 수 있다.
현재 CI(빌드, 테스트)가 Github VM에서 수행되는데, 그 VM에 docker가 기본으로 설정되어 있다고 한다. 따라서 TestContainers를 사용했을 때, 기존 CI 스크립트를 변경할 필요도 없었다.
✔️ TestContainers 관련 이슈
처음에 검색 기능에 대한 테스트가 계속 실패했다. 검색 결과가 존재해야 하지만, 검색되지 않는 이슈가 있었다. 디버깅해보니, 토큰 생성되지 않는다는 것을 알 수 있었다.
fulltext 인덱스의 토큰은 commit이 되는 시점에 생성되는데, @DataJpaTest는 커밋하지 않고 롤백을 한다. 그래서 애초에 토큰이 만들어지지 않아서 검색 결과가 존재하지 않는 것이었다.
이를 해결하려면 각 테스트 메서드에서 커밋을 하도록 해주면 된다. 하지만 단순히 @Transactional을 붙여서는 해결되지 않는다. @DataJpaTest는 이미 테스트 메서드 단위로 트랜잭션을 걸고 롤백하기 때문에, 추가로 @Transactional을 선언해도 결국 롤백에 통합되어 커밋이 일어나지 않기 때문이다.
@Transactional(propagation = Propagation.NOT_SUPPORTED)
class CountByKeyword {
...
}
따라서 @Transactional(propagation = Propagation.NOT_SUPPORTED)를 사용해야 커밋이 이루어진다. 이 설정은 해당 메서드를 트랜잭션에서 제외하기 때문에 쓰기 지연이 발생하지 않고, INSERT가 실행되는 즉시 커밋되어 토큰이 생성된다.
옵티마이저가 어떤 선택을 할지 예측하는 것이 어려운 것 같다. explain을 통해 실행 계획을 확인하고 적절한 인덱스를 적용해주는 것이 중요하다고 느꼈다.