6차 데모데이 백엔드 요구사항에 "목표 TPS 설정 및 서버 설정 최적화"라는 내용이 있었다.
우리 서버가 현재 얼만큼의 부하를 감당할 수 있는지, 목표 TPS를 처리할 수 있는지 확인하기 위해 부하테스트르 진행했다.
그리고 그 과정이 매우 길고도 험난했기에 글로 남기려 한다.
성능테스트를 처음 접하는 사람들이 이 글을 통해 조금이나마 도움을 받으면 좋을 것 같다.
✔️ 부하테스트 목적
지금 당장은 실사용자가 없기 때문에, 사용자가 존재하는 미래를 가정해 부하테스트를 진행하려 했다.
따라서 프리코스 디스코드 혹은 인스타그램을 통해 서비스를 열심히 홍보하고, 이벤트를 개최하는 상황에 운영 서버가 부하를 얼마나 버틸 수 있는지 확인하는 것을 목적으로 삼았다.
✔️ 튜닝 대상 핵심 기능
튜립은 유튜버들의 여행 브이로그에 나오는 장소 정보들을 보기 쉽게 요약해주는 서비스고, 가장 중요한 기능을 꼽자면 "콘텐츠 상세 조회"라고 생각한다. 실제로 응답까지 시간이 오래 걸리는 기능이라, 더욱 성능 튜닝의 대상으로 적합하다고 판단했다.
따라서 사용자가 콘텐츠 상세 페이지를 조회하는 상황을 튜닝 대상 기능으로 삼았다.
✔️ 목표 TPS, 응답 시간
이왕 부하테스트 할 거 꿈을 크게 갖고 목표를 아래와 같이 설정해봤다.
🥅 부하 상황 가정
- 프리코스, 인스타그램 등을 통해 홍보를 하고, 튜립이 기대하는 유저 수는 약 3,000명이다.
- 여행 도메인 특성 상 일상적으로 사용하는 서비스가 아니기 때문에, 활성 계수를 10%로 설정하여, 일일 활성 사용자(DAU)를 300명으로 기대한다.
🥅 목표 TPS
사용자 1명이 평균적으로 컨텐츠 조회 기능을 3초에 한 번씩 요청한다고 가정하면, 300명의 DAU를 기준으로 서버가 처리해야 할 요청량은 100TPS이다.
300명 ÷ 3초 = 100TPS
🥅 목표 응답 시간
빈번히 발생하는 기능에서 응답 시간이 1초를 넘어간다면 사용자 이탈률이 높아질 것이라고 판단하여, 목표 응답 시간은 1초 이하로 설정한다.
✔️ 부하테스트 도구
부하테스트 도구로 Grafana k6를 사용했다.
부하테스트를 진행하기 직전에 모니터링 환경을 CloudWatch에서 Grafana로 옮겼는데, k6는 Grafana로 시각화하기 좋기 때문이다.
다른 도구로는 jmeter랑 ngrinder를 사용해봤는데, jmeter는 상세한 시나리오를 작성하기가 k6보다 어렵다고 느꼈고, gui 기반이라 무겁다는 단점이 있다. ngrinder는 사용하는데 약간 복잡다고 느껴졌다. 이에 비해 k6는 gpt를 이용해서 js 기반 시나리오를 뚝딱 작성할 수 있고, 러닝 커브도 낮았다.
✔️ 부하테스트 환경

k6는 로컬 노트북에서 실행시켰고, 개발 서버에 부하를 줬다.
그리고 가정한 상황인 3,000명이라는 유저수에 맞게 더미데이터를 넣어둔 DB를 이용했다.
✔️ 부하테스트 시나리오
콘텐츠 상세 페이지에서 호출되는 api는 아래 2개다.
- /contents/{contentId}/places (컨텐츠 상세 조회 api)
- /contents/{contentId} (컨텐츠, 찜 여부 조회 api)
(각 api request는 하나의 트랜잭션 내에서 수행되기에, 해당 시나리오에서의 rps는 tps와 동일하다.)
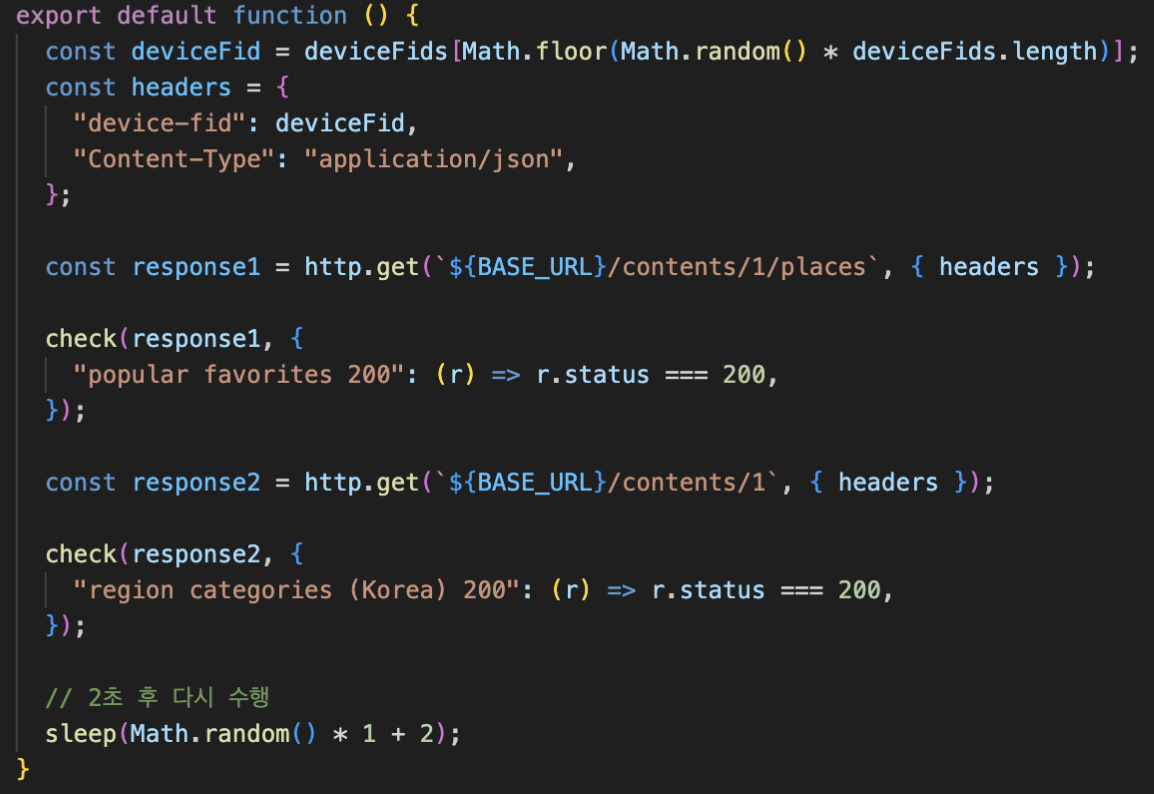
gpt에게 맡기니 시나리오를 js로 잘 작성해줬다.
💻 1th 부하테스트
위의 내용을 바탕으로 부하테스트를 시작했다.

위에서 300명의 동시 접속자를 가정했는데, 우선 지금 서버가 300명을 버티는지 확인하기 위해 부하테스트를 해봤다.
그런데 vu 150부터 RPS 증가하지 않는 것(병목 발생)을 확인할 수 있었다. 따라서 부하테스트 할 때 vu를 200으로 설정하여, 세팅 변경에 따라 병목이 해소되는지 관찰하고자 했다.

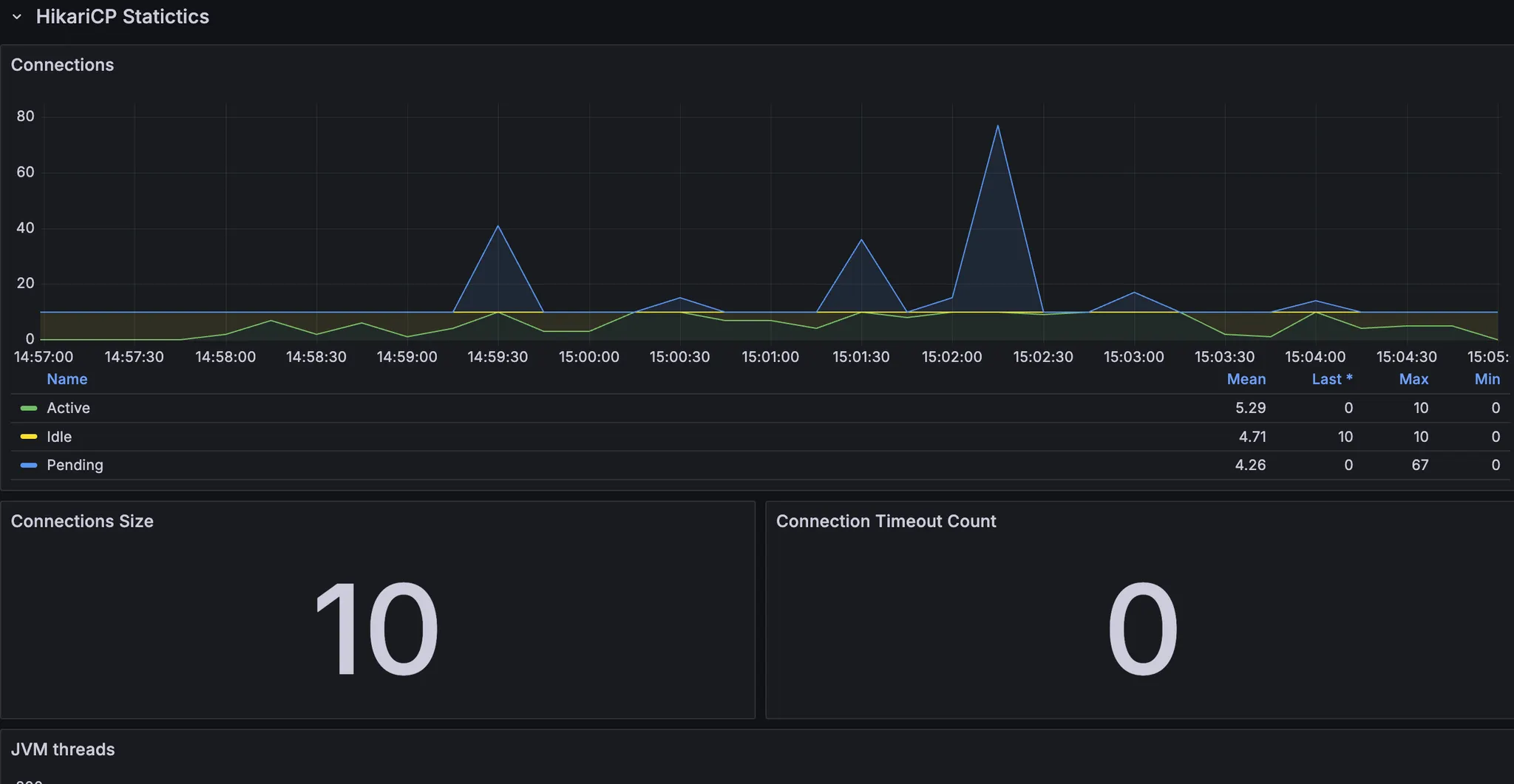

또한 다른 지표들을 기반으로, 병목의 원인과 어떤 세팅을 조절하면 좋을지 분석해봤다.
- 스레드, db 커넥션은 안정적인 것으로 보인다.
- cpu도 올라봤자 70%선에서 유지 → cpu 부하로 인한 처리 속도 저하는 아님
- cpu 시스템 처리량이 한계치 도달? 컨텍스트 스위칭에 많은 비용이 발생 → 스레드 수 줄여보기

이후 톰캣 스레드 수, db 커넥션 수를 조절하면서 테스트했다.
결과적으로 톰캣 스레드를 60개로 설정했을 때가 최적으로 나왔다.
💻 1th 부하테스트 결론
- Tomcat server.tomcat.threads.max = 60
- 스프링 톰캣의 기본 max thread size는 200인데, 모니터링 도구를 통해 톰캣 스레드 현황을 확인했을 때 실제 사용중인 스레드는 한정적이었고, 많은 스레드를 사용하는 구간도 많지 않았다. 스레드 수가 많으면 cpu가 그만큼 많은 작업을 처리할 수 있지만, 컨텍스트 스위칭을 위한 비용이 발생하고, cpu 점유율이 높아지고, 처리 속도는 느려진다고 판단했다.
- Tomcat server.tomcat.threads.min-spare = 60
- 스프링 톰캣의 기본 min-spare thread size는 10이다. 만약 max thread size가 이보다 더 큰 상황에서 10보다 많은 요청이 동시에 들어온다면, 새로운 스레드를 만드는 데에 비용이 소모되고, 스레드는 그동안 큐에서 대기하게 된다. 부하테스트 상황은 많은 사용자가 동시에 접근하는 상황을 가정하고 있으므로, max thread size와 min-spare thread size을 동일하게 설정하여, 스레드를 새로 생성하는 비용을 없애고자 했다.
- HikariCP maximumPoolSize = 10
- 모니터링 도구를 통해 DB의 cpu, HikariCP connection 현황을 확인했을 때 DB에 병목이 발생하는 상황은 아니라고 판단했다. 실제로 maximumPoolSize를 낮추고 높여서 실험해본 결과, 기본 설정인 10일 때보다 rps가 낮아지는 경향을 확인할 수 있었다.
❗️ 1th 부하테스트의 문제
사실 여기까지의 부하테스트에는 수많은 함정, 문제가 존재했다.
문제 1) 개발 서버에 부하테스트하기
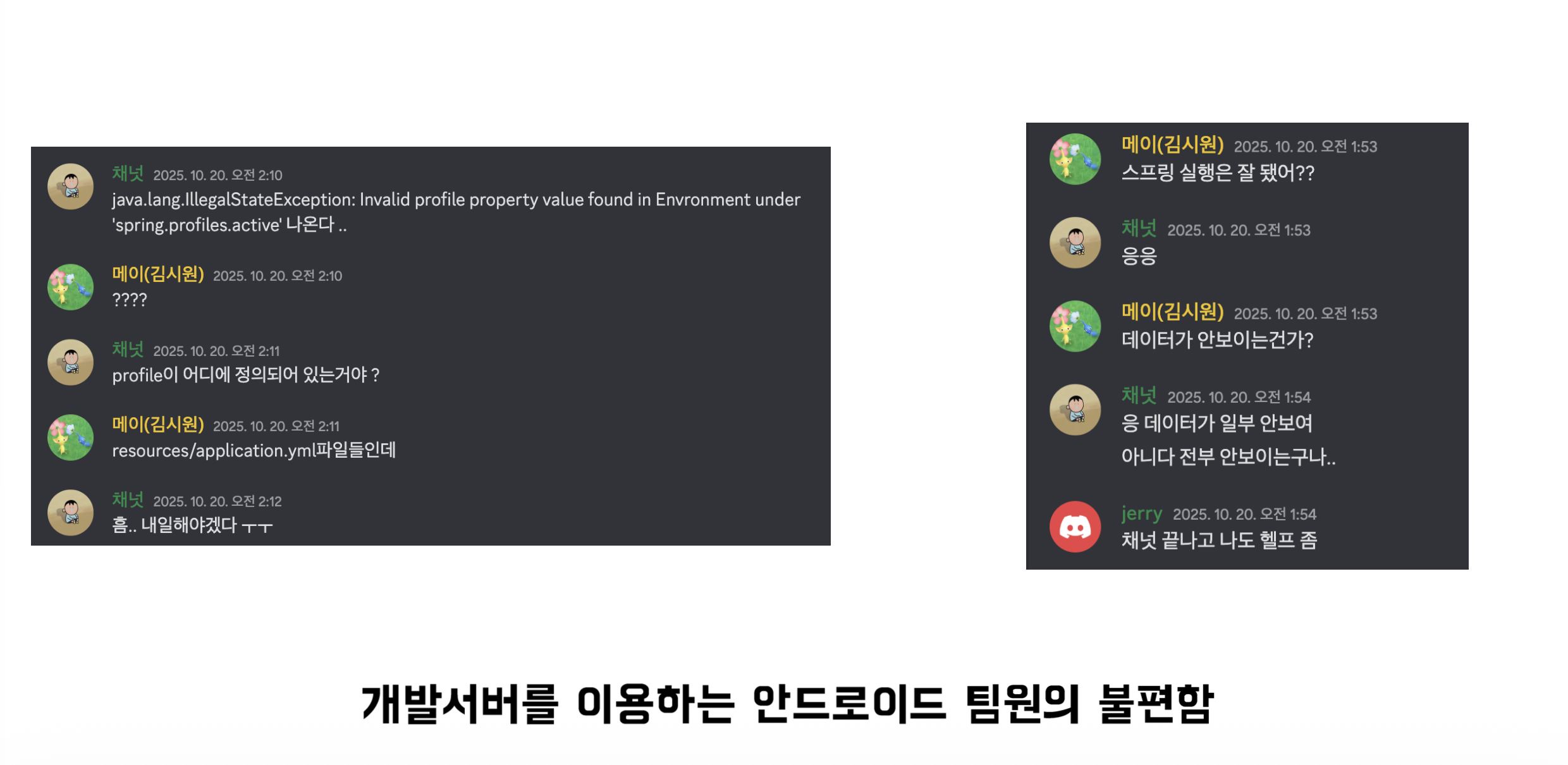
안드로이드 팀원들에게 부하테스트를 하는 동안 개발서버를 이용하지 말아달라고 부탁했었고, 이전 페어 프로그래밍을 할 때도 안드 크루들이 로컬에서 서버 띄워서 개발하는 방법을 많이 이용했었기 때문에, 큰 문제가 없을 것이라고 생각했었다.
그런데 로컬에서 서버를 실행시키기 위해 도커, 프로필, 환경변수 설정까지 해줘야 하다보니 막히는 부분이 많았고, 안드 크루들이 많은 불편함을 겪었다. 따라서 개발 서버에서 부하테스트 하면 안 되겠다고 느꼈다.
문제 2) 로컬에서 k6 실행하기
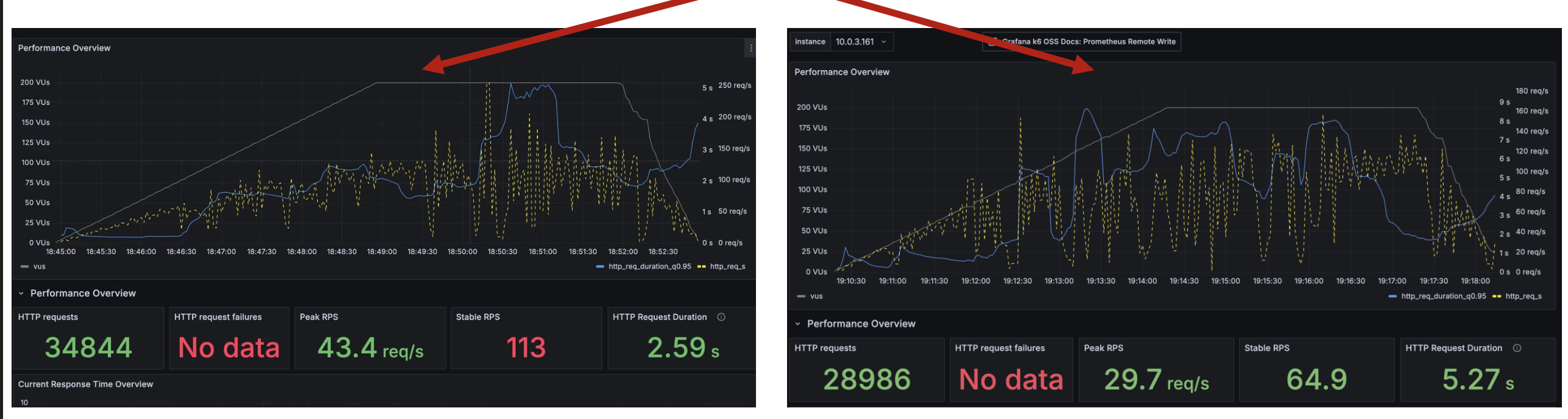
톰캣 스레드를 60으로 설정했을 때 최적의 결과가 나와서, 확인차 한 번 더 실행시켰는데 TPS가 반토막이 났었다. 내 로컬 노트북 환경에 따라 k6가 보내는 요청이 영향을 받았고, 그에 따라 결과도 일관적이지 않았다.
k6를 돌리는 환경은 항상 일관적으로 맞춰줄 필요가 있다고 느꼈다.
문제 3) 렌더링 시간을 고려하지 않은 목표
앞서 응답시간 목표를 1초로 설정했는데, 렌더링 시간까지 고려하면 응답 시간 목표는 더 작아야 한다고 생각했다.
문제 4) 마인드셋
최적의 세팅을 찾기보다는 목표 수치를 달성시키는 것을 항상 마음에 새기자. 최적을 찾기 위해 반복적인 부하테스트를 진행하는 것은 가성비가 떨어진다는 것을 몸소 느꼈다.
실제로 코치님이 주신 피드백중 아래 내용이 가장 인상깊었다.
목표 수치가 없으면, 테스트를 그만 해야하는 시점을 정하기 어려움. 성능 테스트 자체에 매몰되어 최대 퍼포먼스 지점을 찾아내기 위해 테스트를 반복하는 문제를 겪을 수 있음. 1순위 목적은 서비스에서 서버가 안정적으로 처리할 수 있는 TPS를 대략 확인하는 것! 서버 1대의 최대 성능 지점을 연구하는 목적이 아님!
💻 2th 부하테스트

1차 부하테스트에서 느낀 문제점들을 개선하여 2차 부하테스트를 진행했다.
2차 부하테스트에서 내가 꽂힌 부분은 CPU 사용률이었다. CPU 사용률이 100% 근처에서 놀면 서버가 내려갈지도 모른다는 인식이 있었고, 이를 낮춰야 한다는 생각에 사로잡혔다. (경험상 ec2가 터졌을 때 모니터링 지표를 확인하면 항상 CPU가 100%까지 치솟았었기 때문)
그래서 CPU 사용률을 낮추기 위해 힙메모리 제한을 늘려봤다. 기존 운영 서버 힙메모리 제한을 1024MB로 줬었는데, 1536MB까지 늘려봤다. (참고로 운영 서버 ec2 스펙은 t4g.small로, 메모리가 2GiB이다)

GC 횟수가 줄은 만큼 일해서 그런지 TPS가 높아지기는 했다.

목표 TPS 100, 목표 응답 시간 500ms를 달성했던 5차 테스트의 세팅보다, CPU 사용률이 안정적이었던 6차 테스트의 세팅을 최적으로 판단했었다.
❗️ 2th 부하테스트의 문제
2차 부하테스트도 내가 고려하지 못한 부분이 많았다. 여기까지의 내용을 스터디에서 공유했었는데, 감사하게도 많은 피드백을 받을 수 있었다. 정리해보면 아래와 같다.
피드백 1) cpu 100프로에서 놀면 왜 안좋음? ec2 터진건 메모리때문 아님?
맞다. cpu가 100%라고 무조건 위험한 상황인 것이 아니다.
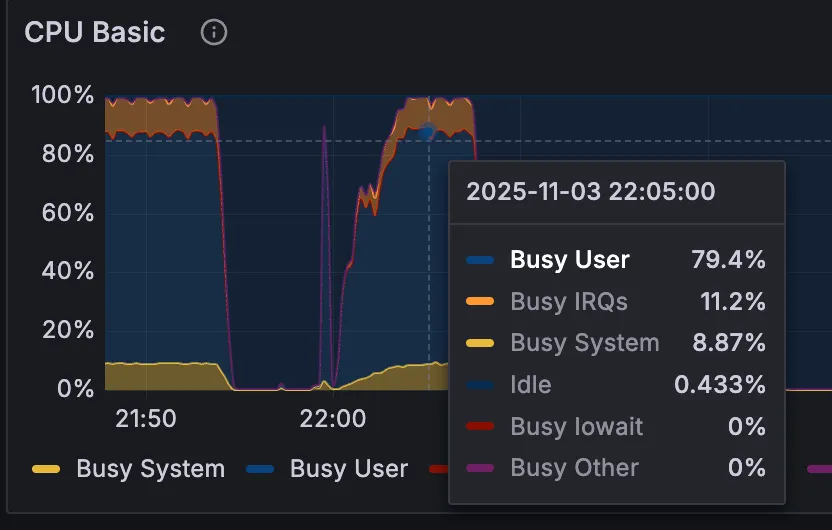
부하테스트 중 cpu 메트릭인데, 이 항목 중에서 Busy User가 80%인 것은 cpu가 연산에 80%를 쓴다는 것이다. 머리를 쓰느라 80% 동작하는 것이므로 괜찮다. 대신 다른 항목이 높은 비율을 차지할 때는 눈여겨봐야 할 것 같다.
피드백 2) 힙메모리 기본 설정이 하드웨어의 1/4에요
https://www.baeldung.com/spring-boot-default-memory-settings?utm_source=chatgpt.com
전혀 모르고 있던 사실인데, Baeldung에서 확인할 수 있었다.
우리 서버 스펙으로 따지면 힙메모리 제한이 기본 512MB으로 걸려있다.
운영서버가 한 번 내려간 적 있었는데, 원인이 jvm OOM이었고, 힙메모리 제한을 두는 것을 해결책이라고 판단해서 1024MB의 제한을 설정했었다. 그리고 이 때 스왑메모리도 같이 설정했어서 이후에는 서버가 안정적으로 유지됐었다.
이 제한이 있는줄 모르고 설정한 내용이고, 기본값이 1/4이라면 일단 이 기준에 따라보자고 생각했다.
피드백 3) 콘텐츠id 랜덤하게 조회해봐라
기존 시나리오상 content_id=1로만 조회하고 있었는데, 이렇게 할 경우 db 메모리에 캐싱되어 실제 환경보다 성능이 좋게 나올 수 있다는 것을 알게 되었다.
💻 3th 부하테스트
받은 피드백을 기반으로 다시 한 번 부하테스트를 진행해봤다.
사실 부하테스트까지는 아니고, 피드백 내용을 직접 확인해보고 싶었다.
우선, CPU 100%가 오랜시간 유지되어도 서버가 안정적인지 확인하기 위해, 안정기를 20분으로 늘려봤다.

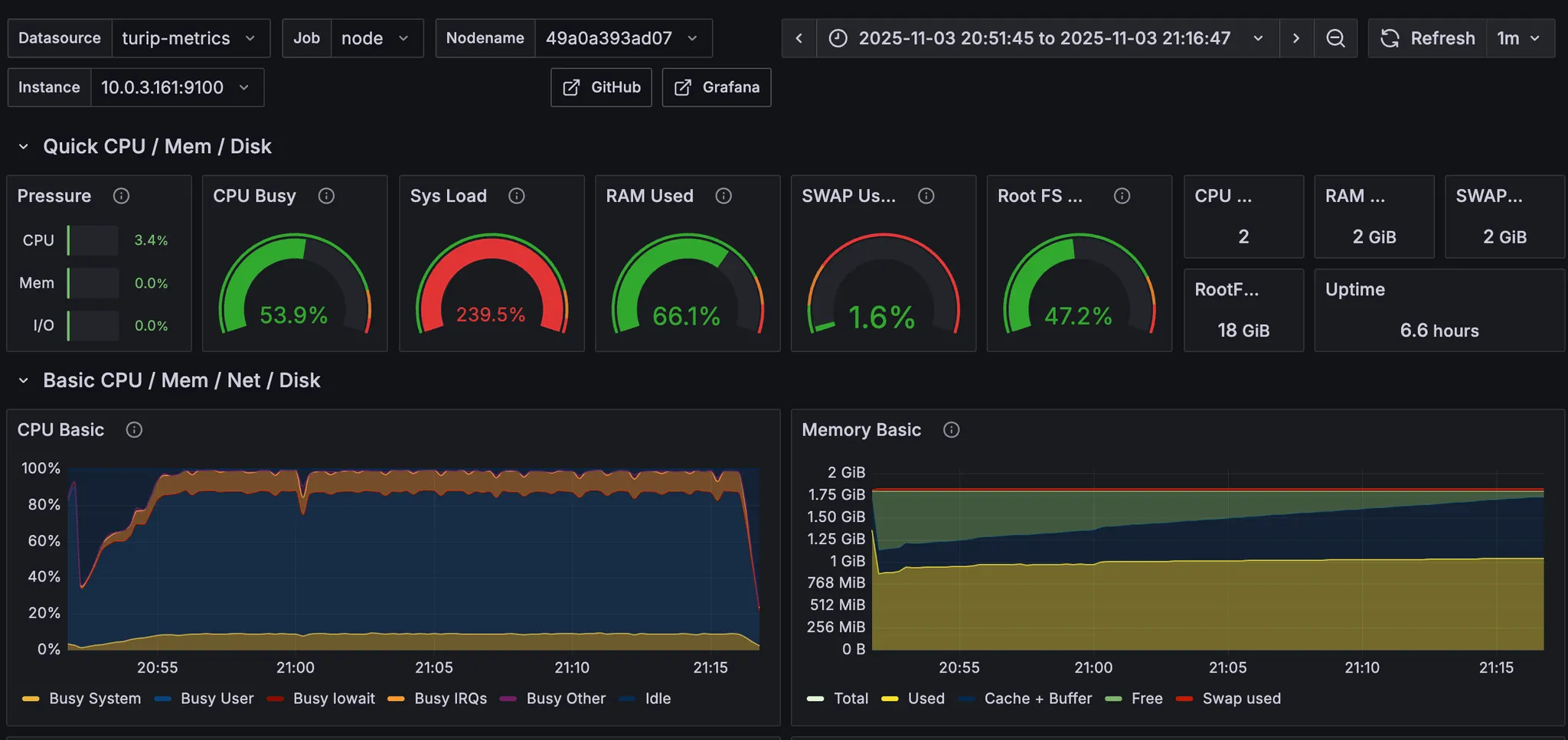
터지지도 않고 요청도 안정적으로 처리하는 것을 확인할 수 있다.
그 다음으로는 힙메모리 제한을 없애고 서버를 실행시킨 뒤 부하를 줘봤다. 힙메모리 기본 설정이 512MB인지 확인해보고 싶었고, 기본 설정일 때 성능이 많이 안좋아지는지 확인하고 싶었다.

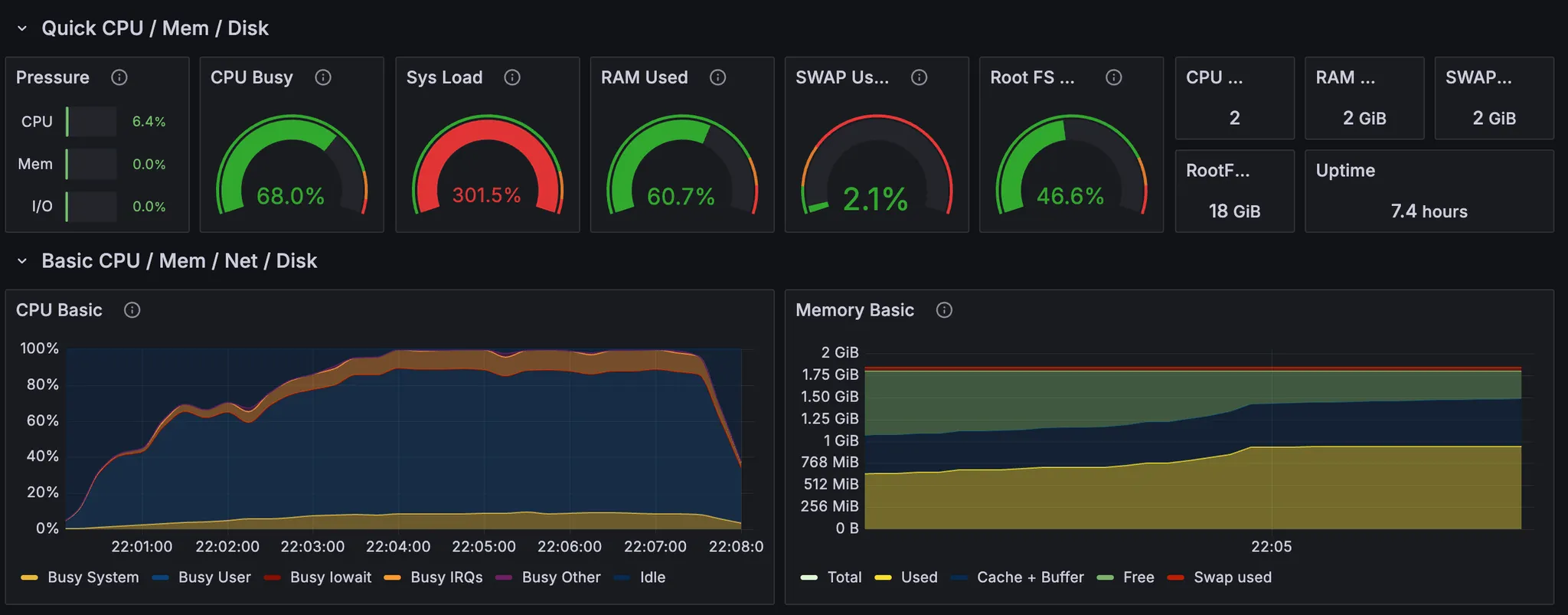

GC 빈도도 많아지고, stop the world 시간이 길어졌다. TPS와 응답시간도 목표치에 도달하지 못한다.
💻 3th 부하테스트 결론
3차 부하테스트를 진행하면서 정리한 생각은 아래와 같다.
⇒ CPU 100%를 무조건 경계하지 말자!
1th, 2th 부하테스트를 할 때는 지금까지의 경험을 기반으로 cpu 100%가 무조건 불안정적 서버로 이어질 것이라고 생각했다. 왜냐하면 ec2가 터졌을 때 모니터링을 확인해보면 항상 cpu가 치솟았었기 때문에.
그런데 스터디 피드백 듣고 생각해보니, cpu 100%는 머리를 100% 쓴다고 볼 수 있는데 안 좋다고 할 수 있는지, cpu 사용률을 낮추기 위해 성능이 가장 좋았던 세팅을 선택하지 않는게 적절할지에 대한 의문이 생겼음
실제로 CPU 100%를 유지하면서 부하를 길게(20분간) 주는 테스트를 진행해봤는데, 그 결과 ec2가 터지지 않았고, cpu 사용률이 높은 것 자체는 문제가 되지 않는다는 것을 알게 되었다. 모니터링 지표에서 cpu 사용률 100% 중 user 영역이 80%를 점유한다는 것을 확인한 후, 이후 부하테스트 의사결정 과정에 cpu 사용률을 주요 고려 요소에서 제거해도 된다는 결론을 내림
⇒ 힙메모리 제한 설정하지 말자!
jvm 기본 설정과 우리의 서버 환경(메모리 2GiB) 상, 기본으로 할당되는 힙 메모리 크기는 512MB
그리고 우리가 설정했던 운영 서버 힙 메모리 크기가 1024MB, 2th 부하테스트 과정에서 힙 메모리 1536MB까지 늘렸었음
jvm 메모리가 부족해 OutOfMemeory가 발생하는 경우 서버가 내려갈 수 있다. 그런데 jvm의 메모리 구조 중 힙 영역 말고도 다른 영역까지 고려했을 때 힙 영역에만 1524MB를 할당하면 OOM이 발생할 수 있을 것 같다고 판단했음. 그래서 일단 기본으로 제공하는 설정을 따르자고 생각했음
힙메모리를 높였을 때 GC 빈도, stop the world 시간이 단축되어 성능이 개선됨을 확인했으나, 안정적인 서버 운영이 우선이라고 생각했음. jvm에 대해 더 깊게 학습하여 동적 메모리 영역의 용량을 정량적으로 예측한 뒤 근거있는 힙메모리 제한을 설정해야겠다고 판단함.
여기까지의 내용을 바탕으로, 4차 부하테스트를 진행하려 했는데 아직 못 했다.
4차 부하테스트의 목적은 "content_id 랜덤하게 설정하고, 힙메모리 제한 없애고, CPU 신경쓰지 말고, TPS와 응답 시간 목표를 충족하는 세팅값을 찾는 것"이다.
할 때마다 아쉬운 점이 남아서 부하테스트를 못 놓고 있는데, 4차 부하테스트까지 잘 마무리해서 2편으로 포스팅할 수 있으면 좋겠다 🤓