현재 진행하는 프로젝트에서 검색 기능을 지원하기 위해 fulltext index를 사용중이다. 세 개의 컬럼에 fulltext index를 걸어주고 있고, n-gram size도 1로 설정했기 때문에, 인덱스 용량을 고려해보면 좋겠다고 생각했다.
인덱스 크기를 고려해야 하는 이유 중 하나가 버퍼풀 cache miss로 인한 disk i/o 과다 발생이라는 것을 알게 됐고, 해당 내용을 중심으로 검색 기능을 개선한 과정을 정리해봤다.
이 글의 모든 내용은 MySQL innodb 엔진 기준으로 설명할 것이다.
📍 디스크 I/O

데이터베이스의 데이터들은 디스크에 영속화된다. 그런데 디스크에 존재하는 데이터에 접근하는 시간은 메모리에 접근하는 시간에 비해 매우 느리다. 만약 HDD에 접근한다 하면 최대 약 100,000배까지 차이가 난다.
따라서 최근 사용한, 혹은 자주 사용되는 데이터는 다시 접근할 확률이 높기 때문에, 메모리 공간에 올려두고 사용한다.
📍 버퍼풀

MySQL innodb에서 디스크에서 가져온 데이터는 버퍼풀이라는 메모리 공간에 저장된다. 버퍼풀에 저장되는 것은 테이블, 인덱스 데이터로, 물리 메모리의 최대 80%까지 할당 가능하고, 페이지(db의 메모리 관리 단위, 16KB) 단위로 동작한다.
참고로 innodb의 기본 버퍼풀 크기는 128MB로 할당되어 있다.
✔️ 구조
버퍼풀에서 페이지들은 Linked List 구조로 저장된다. 자주 쓰이는 페이지는 앞부분에 존재하고, 사용 빈도가 적을수록 뒤로 밀려나며, 버퍼풀 공간이 부족할 경우 오래된 페이지는 버퍼풀에서 쫓겨난다.
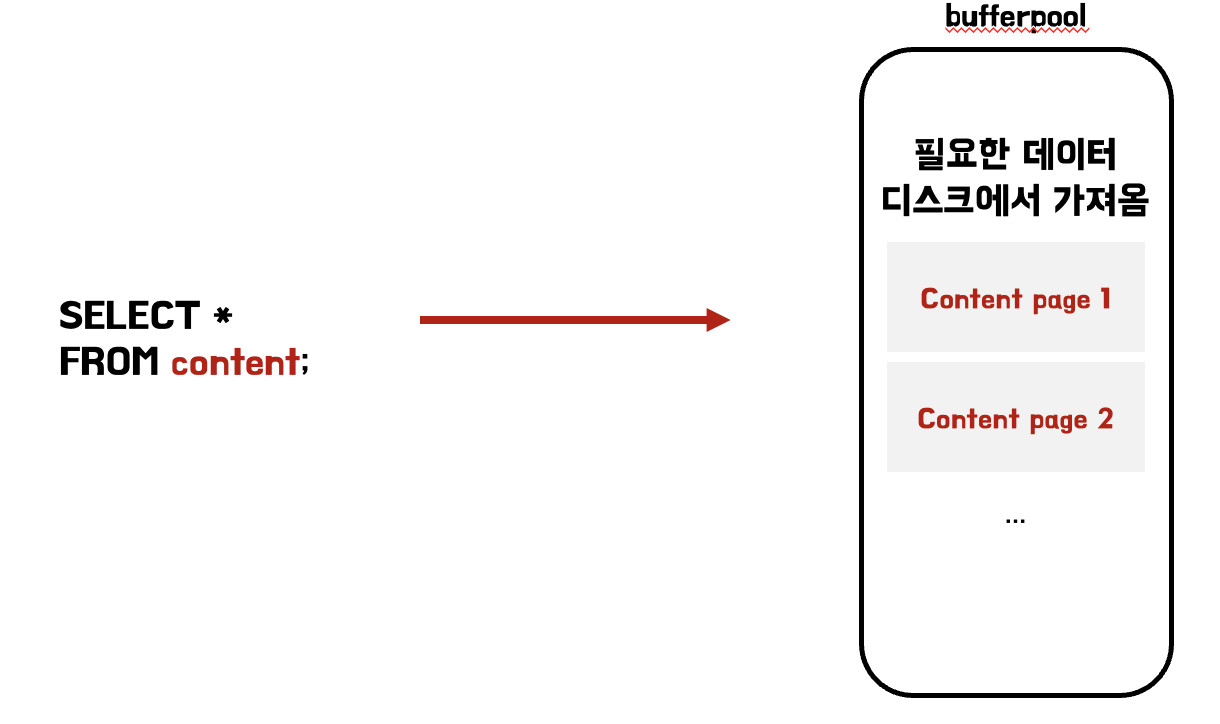
쿼리를 날리면, 필요한 데이터들이 존재하는 페이지를 디스크에서 가져와 버퍼풀에 올린다. 이후 버퍼풀에 올라온 데이터에 다시 접근하는 경우 디스크 i/o가 발생하지 않아 빠르게 조회된다.

만약 버퍼풀의 남는 공간이 없는 경우, 사용한지 오래된 페이지를 버퍼풀에서 제거한 뒤 새로운 페이지를 불러온다.
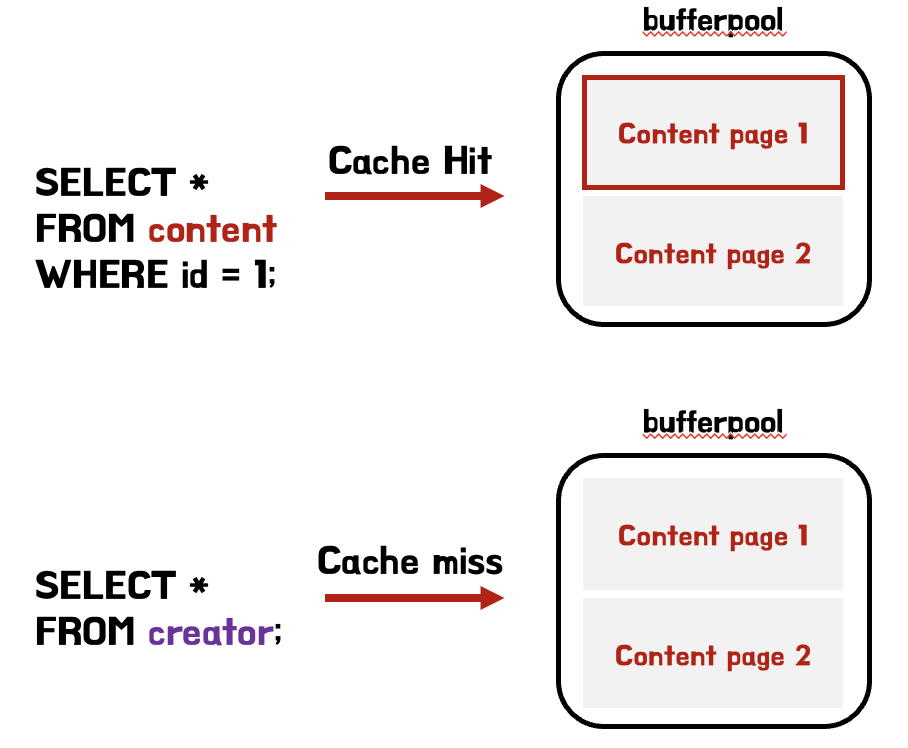
만약 조회하고자 하는 데이터가 버퍼풀에 존재하지 않는 cache miss가 자주 발생하는 경우, 많은 디스크 i/o가 발생하여 성능에 악영향이 있을 것이다.
인덱스를 열심히 걸어줬는데도 슬로우쿼리 문제가 해결되지 않는 경우, 버퍼풀 메모리 부족으로 인한 디스크 i/o 증가를 의심해볼 수 있다.
✔️ innodb_buffer_pool_instances
db의 용량이 커서 버퍼풀에 할당할 수 있는 크기가 큰 상황을 가정해보자. 그러면 버퍼풀에 올릴 수 있는 페이지도 많아지고, cache hit이 발생할 확률, 즉 LRU 리스트에서 원하는 페이지를 탐색하는 작업이 발생할 확률이 높아진다. 그런데 페이지를 읽거나 쓸 때, 페이지 구조, 순서에 변화가 생길 수 있으므로, LRU 리스트에 락을 걸게 되고, 경합이 발생하게 된다.
이를 개선하기 위해 MySQL은 버퍼풀을 여러 인스턴스로 나눠 관리하는 기능을 제공한다. 버퍼풀 인스턴스는 각각 독립적인 LRU 리스트를 관리하기에, 많은 스레드가 동시에 읽고 쓰는 상황에서 성능이 크게 개선된다. 공식 문서에서는 하나의 버퍼풀 인스턴스에 대해 최소 1GB정도 할당하는 것을 권장한다.
📍 검색 쿼리에서 사용하는 인덱스 용량 확인
현재 서비스의 검색 쿼리에서 사용하는 인덱스 용량을 확인해서, 버퍼풀을 충분히 이용할 수 있을지, 혹은 용량이 너무 커서 cache miss가 자주 발생할지 예측해보려 한다.
✔️ 튜립 서비스의 검색 기능
서비스의 검색 기능을 간단히 설명하자면 아래와 같다.

서비스 정책 상, 콘텐츠명, 크리에이터 채널명, 콘텐츠 속 장소들의 이름들을 기반으로 검색한다. 즉 3개의 테이블의 3개의 컬럼을 이용한다. 이 3개의 컬럼에 각각 fulltext index를 걸어줬고, n-gram size는 1로 설정해두었다. n-gram size를 1로 설정한 이유는, 여행 도메인이라는 특성상 "빵", "봄"과 같은 검색어를 지원해줘야 한다고 생각했기에, 검색 정책으로 1글자 검색도 가능하게 했기 때문이다.

검색 쿼리는 위와 같다. 각 컬럼에 대해 전문검색을 수행한 뒤 union으로 결과를 합쳐주고 있다. 관련 내용은 이전 포스트에 작성해두었다. https://seaniiio.tistory.com/14
✔️ 테스트 환경

테스트 환경은 운영 환경 db와 같은 스펙으로, t4g micro(1GiB)에 MySQL을 띄워서 사용했다. 가장 중심이 되는 content 테이블에 10만개의 더미데이터를 넣어줬고, 서비스적인 연관성을 고려하여 creator, place에도 더미 데이터를 적절히 넣어줬다.
✔️ fulltext index 크기 확인

3개의 컬럼에 대해 fulltext index를 걸어줬는데, 심지어 n-gram size 1로 설정했기에 용량이 매우 클 것이라고 예상했었다. 그런데 직접 확인해본 결과, 생각보다 많은 용량을 차지하지 않았으며, n-gram size 2일때와의 용량 차이도 약 12MB정도 나는 것을 확인할 수 있었다.
✔️ 클러스터드 인덱스 크기 확인
클러스터드 인덱스에서는, 인덱스의 key값(pk)과 함께 해당 레코드의 실제 데이터들이 리프 노드에 저장된다. 따라서 key값과 pk만을 저장하는 세컨더리 인덱스보다 훨씬 많은 용량을 차지하게 된다.
검색 쿼리에서 사용하는 테이블들(content, creator, place)의 인덱스 크기를 확인했을 때 아래와 같았다.

place 테이블의 클러스터드 인덱스 크기가 상당했다. 그런데 검색 쿼리를 실행했을 때 place의 클러스터드 인덱스도 버퍼풀에 올리는 것을 확인할 수 있었다.

그런데 위에 올린 검색 쿼리를 보면 알 수 있듯이, 우리가 검색 쿼리에서 궁극적으로 얻고자 하는 것은 content에 대한 데이터뿐이다. 그런데 id 말고는 사용하지도 않는 place의 데이터(클러스터드 인덱스)를 버퍼풀에 올린다는 것은 상당히 비효율적이라고 생각했다.
현재 버퍼풀 크기가 128MB인데, 만약 검색어가 엄청 다양해서 place에 대한 많은 클러스터드 인덱스가 버퍼풀에 자주 올라가고, 버퍼풀의 페이지가 자주 교체된다면, cache miss rate가 증가할 것이고, 디스크 i/o가 증가할 것이다.
그래서 검색 쿼리를 수행할 때 content에 대한 클러스터드 인덱스만 버퍼풀에 올리는 방법에 대해 고민해봤다.
📍 개선 방향: 검색 전용 테이블

애초에 join을 할 필요가 없도록, 검색에 필요한 텍스트들을 하나의 컬럼으로 관리하는 방법을 생각했다. 예를 들어 content.title이 "수원 행궁동 브이로그", creator.channel_name이 "튜립", 콘텐츠 속 장소의 이름들이 "골디스 행궁점", "아웃백 스테이크하우스", "인생네컷" 이라면, content_search.search_text에 "수원 행궁동 브이로그 튜립 골디스 행궁점 아웃백 스테이크하우스 인생네컷"으로 저장한다.

만약 검색 전용 테이블을 둔다면 검색 쿼리가 이렇게 변경된다. 검색 결과에 사용하지 않는 creator, place 테이블을 조인하지 않기 때문에, 버퍼풀에 creator, place 인덱스가 올라오지 않을 것이라고 기대했다.
✔️ 검색 전용 테이블 인덱스 크기 확인
검색 전용 테이블을 뒀을 때의 풀텍스트, 클러스터드 인덱스의 크기를 확인해봤다.

참고로 위에서 사용한 더미데이터를 기반으로 content_search 테이블을 만든 것이므로, 검색에 사용하는 텍스트 양과 검색 결과 자체는 동일하다. 각각의 컬럼에 대해 인덱스를 걸었을 때에 비해 용량이 많이 줄었는데, 검색에 사용하는 컬럼 외 다른 컬럼이 존재하지 않고, 레코드 수 자체도 content의 크기와 같은 10만개이기 때문에 줄었다고 예측했다.
📍 개선 전, 후 비교하기
✔️ 버퍼풀 비교하기
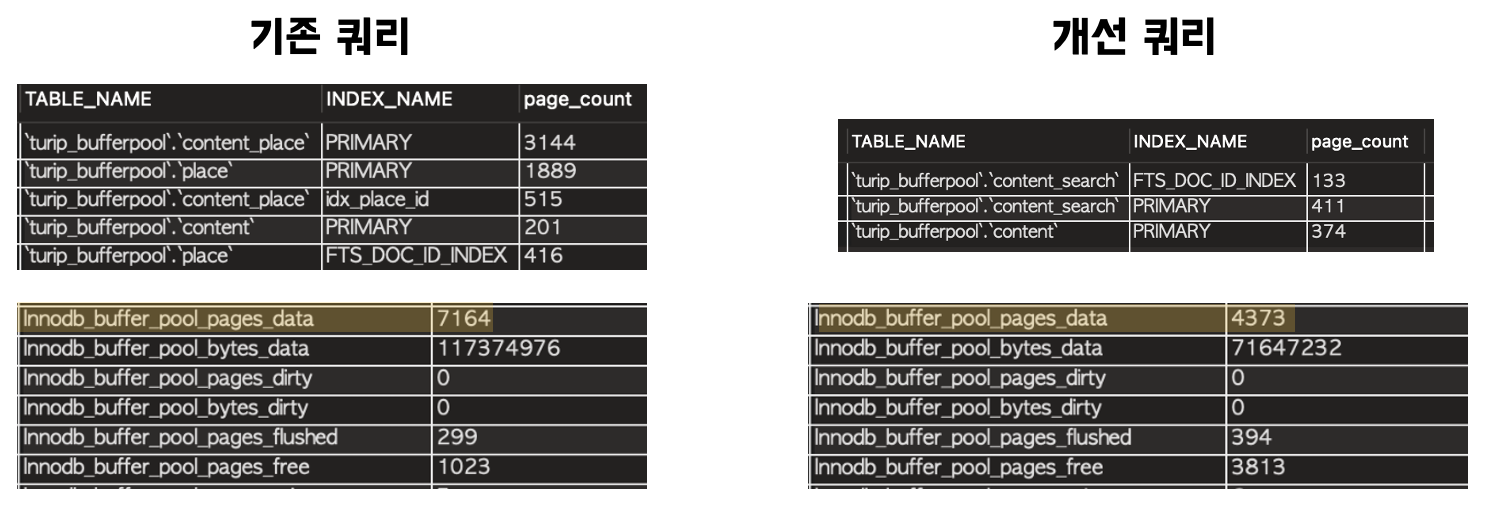
왼쪽은 기존 쿼리를 수행한 뒤 버퍼풀에 올라온 페이지 결과고, 오른쪽은 검색 테이블을 두었을 때의 결과다. 기존에는 조인에 사용하기 위한 content_place(content와 place의 중간 테이블), place 관련 페이지가 많은 비중을 차지하고 있었으며, 개선 후에는 정말 필요한 페이지만 버퍼풀에 올라오는 것을 확인할 수 있었다.
하나의 검색어에 대해서 이렇게 차이가 났는데, 다양한 검색어로 검색해 많은 페이지를 버퍼풀에 올린다면 더욱 많은 차이가 날 것으로 예상한다.
✔️ 쿼리 속도 비교하기

쿼리 속도 자체도 조금은 개선된 것을 확인할 수 있었다. join, union 과정이 줄어들다보니 시간이 자연스레 단축되었다.
📍 검색 전용 테이블의 장/단점
이렇게 검색 전용 테이블을 두면 많은 문제가 해결되는 것으로 보이지만, 고려해야 할 단점들도 존재한다.
✔️ 장점
- 버퍼풀 사용량 ↓, cache hit rate ↑
- 쿼리 단순화, 속도 개선
- 다중 컬럼 검색 지원(콘텐츠 제목에 “도쿄”, 장소 이름중에 “라멘” 존재하면 “도쿄 라멘” 검색 가능, 기존에는 컬럼별로 전문검색을 수행했기 때문에 검색되지 않았다)
✔️ 단점
- 검색 정책에 의존하는 테이블: 예를 들어, 장소명은 검색되지 않도록 정책을 변경한다면, 검색 테이블의 데이터들을 업데이트해줘야 한다. 즉, 서비스 정책의 변화가 db단에도 영향을 주게 된다.
- content, creator, place 데이터에 의존: 콘텐츠 제목이 수정된다면 검색 테이블의 검색 쿼리도 함께 수정해줘야 한다.
이렇게 정리해봤을 때 생각보다 단점이 크지만, 현재 content, creator, place 테이블의 쓰기 작업은 개발자에 의해서만 일어난다는 점, insert만 존재하고 update, delete는 지원하지 않는다는 점에서 단점이 크게 작용하지는 않을 것 같다.
📍마무리
사실 버퍼풀 크기를 늘려준다면, 개선 전 쿼리에 대한 모든 인덱스도 버퍼풀에 충분히 올릴 수 있을 것이고, full hit를 기대할 수 있다.

MySQL 공식문서에 따르면, 버퍼풀 크기는 시스템 메모리의 50 ~ 75% 할당을 권장한다고 나와있다. 따라서 현재 사용중인 t4g.micro 인스턴스를 기준으로 약 500 ~ 750MB를 할당하도록 설정해야겠다.
운영 db에 쿼리를 날려 cache hit 현황을 주기적으로 확인해보는 것도 좋을 것 같다. 만약 hit rate이 많이 떨어진다면, 버퍼풀 크기를 늘려주는 것을 고려하거나, 정말 필요한 인덱스가 올라가고 있는지 확인한 뒤 개선해볼 수 있을 것이다.
'DB > MySQL' 카테고리의 다른 글
| [MySQL] 인덱스 (2) | 2025.09.15 |
|---|